Forum Replies Created
-
AuthorPosts
-
::
Here is the answer from Simon:
Sorry about the delay in replying. Generally you have a few different options in doing this, each with different tradeoffs. For instance, you could conditionally compile the test code into the same dll (e.g. define a configuration in your build system which activates some preprocessor macro). This way you can have easy access to all the internals, at the cost of some additional build complexity.
My preferred way would be to also include the sources of the dll into your test build. This will depend a lot on which build system your using. With CMake, for instance, you can define an “Object Library” with all the internals of your dll, and set that as a dependency of your dll and your tests. That way they all your sources just get built once and linked into both endpoints. Alternatively, you could produce a static library with the internals which both link against.
::Consider the following contrived example: https://godbolt.org/z/bq6xjn6YG:
int nonConstInt = 10; const int* pToNonConstInt = &nonConstInt; const int* pToConstInt2 = const_cast<const int*>(pToNonConstInt); int* pToInt2 = const_cast<int*>(pToConstInt2); *pToInt2 = 12; // fine std::cout << nonConstInt << '\n';
nonConstInt is original non constant. Meaning, adding and removing constness and modifying it is fine.
::There is a simple trick. Read the pointer expressions from right to left:
Foo * fp0 = GetFoo(); // pointer to Foo Foo *const fp1 = GetFoo(); // const pointer to Foo Foo *const fp2 = GetFoo(); // const pointer to Foo const Foo * fp4 = GetFoo(); // pointer to Foo that is const (pointer to const Foo) Foo *const fp5 = GetFoo(); // const pointer to Foo const Foo *const fp6 = GetFoo(); // const pointer to Foo that is const (const pointer to const Foo)
::The Visual Studio blog describes how to test dlls. They export the stuff: https://learn.microsoft.com/en-us/visualstudio/test/walkthrough-writing-unit-tests-for-cpp-dlls?view=vs-2022.
If this does not help, I’m happy to forward your question to Simon Brand. He is one of the authors of this blog, and I know him.
27. January 2023 at 08:39 in reply to: Thread sanitizer not able to detect deadlock on a data structure like a map? #367521::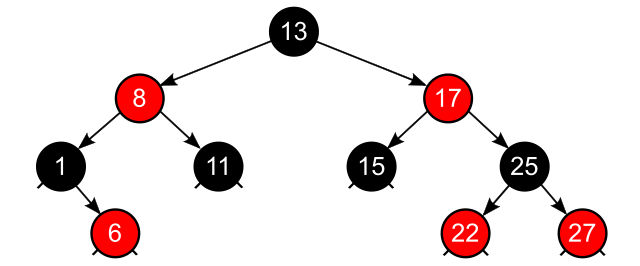
By Nomen4Omen – Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=102283209
Thread Sanitizer observes single memory locations, and has no C++ related semantics. When you have a concurrent read operation on node 6 and a concurrent write operation on node 22, Thread Sanitizer is not aware that nodes 6 and 22 belong to the same data structure. Node 6 and 22 are different memory locations.
Consequentially, Thread Sanitizer will, in general, not detect this data race.
::In modern C++, we model borrowing by pointer/references and owning by values.
This means, the call lk.mutex() borrows it mutex, but the call lk.release() transfers the ownership of the mutex similar to std::move. Meaning, when someone calls delete, unlock, free … on a pointer/reference, it breaks the fundamental assumption in modern C++.
Here is possible use-case for lk.mutex() call on a std::unique_lock<std::mutex> lk. Assume, you have a long-running c function that only accepts a pointer to a mutex.
std::mutex m; void func() { std::unique_lock<std::mutex m> lk(m); longRunningCFunction(lk.mutex()); .... }
This give you the guarantee that the mutex m is locked while the c function is executed. When you invoke the function with a pointer to the mutex m, there is no guarantee provided that the mutex is automatically unlocked. You have to do it explicitly.
std::mutex m; void func() { m.lock(); longRunningCFunction(&m); .... m.unlock(); }
::I’m not aware of any rule for statics, but I strongly suggest the definition of statics inside the class.
class Test { static inline int preferred{}; static int notPreferred; }; int Test::notPreferred{}; int main(){ Test test; }
Defining preferred inside the class makes your code more compact and you cannot forget it.
::I’m not sure if I fully understand your architecture, but I see another architecture. For me, this is a typical producer (thread 1)/consumer (thread 2) scenario.
Furthermore, I’m pretty sure that you have a few serious race conditions in your architecture. Here are my first thoughts:
Both threads are connected by a thread-safe queue. Thread 1 pushes a file path into the queue, thread 2 pulls a file path out of the queue. Due to the decoupling of both threads, this architecture is thread-safe. Additionally, thread 2 is notified, if a new file path is in the queue. In C++11, you should only use a std::condition_variable for this notification. In C++20, you should use a std::atomic_flag for the notification. If consuming takes more time than producing, you can use more than one consuming thread.
You have to ensure that thread 1 pushes all existing file paths into the queue when it starts.
If you don’t know how to implement a thread-safe queue, study the one in my concurrency book.
::Wow. I quote your question in my answer. A few of your questions are answered in week 29. So, let me delay these answers:
A Mutex remembers each thread waiting on it. How is implemented the mutex in C++ (or even in Operating System level) to keep tracking of all those waiting threads?
There are many ways to implement mutexes. The concrete implementation depends on your platform. Here is the short answer: https://en.wikipedia.org/wiki/Mutual_exclusion
How are signaled the threads waiting on a mutex, semaphores, atc.?Which thread is signaled first?
This is a fairness question and depends on the implementation. Most do a first-comes first-serve approach.
Can a mutex be static object?
Of course.
What is the best way to declare mutexes: global, static, class member variables, etc.?
There is no best way. This depends on the use case. Here are few ideas:
- Protect a global with a global mutex
- Protect one instance of a class with a class member mutex
- Protect all instances of a class with a static class mutex
Can we attach/join again to a thread-of-execution which is running as daemon/standalone after (being detached)?Can we bring this thread-of-execution under control again?
No, this would cause an exception.
Was it impossible to update the class std::thread (with joining in destruction and make it cancellable/stopable) instead of creating a new class std::jthread?
When the semantics of std::thread would change with C++20, your code would behave differently.
How the Atomic operation is guaranteed in C++ or even in Operating System? How the Scheduler gets the information to let a thread run, until it finished all the stuff marked as atomic?
I cannot give you an answer in one sentence. Essentially, it is based on the acquire-release semantics on atomics and that the acquire-release semantics establish an inter-thread happens-before relation that does also apply to non-atomics. This post Acquire-Release Semantics should give you a first impression. For more details, you should read my concurrency book.
Static variables with block scope are initialized in C++11 in a thread-safe way. Does this hold for static member variables of a class?
No.
What is a good use case of thread_local variables? What is the difference to the normal variables passed by value?
You have to be patient. thread_local is content of the next week. I also explain it in my videos.
::Here are my thoughts about what I understand so-far.
You have a push system. The data sink is the file folder. The workflow starts with a NewFile in the folder.
This is the flow of data.
NewFile -> InputSource -> Balancer -> Worker_1 -> Worker_2 … -> Worker_n
Now, to your question about your two options:
- The Pipes-and-Filters architecture essentially starts with the workers. You cannot exchange the “filters” before.
- All filters implement a common interface and they are interchangeable.
In the first case, I would not call the three components NewFile, InputSource, and Balancer. This has the consequence that they are pretty difficult to exchange. In the first case, all components, including the three first components, are easy to exchange because they implement a common interface.
From a consistency point of view, I prefer version 2. You have one Pipes-and-Filters architecture and can reason about the entire architecture. You should also consider if you may change in the future the steps before the Balancer. In this case, I strongly prefer version 2 because also components must implement the filter-Interface, and can, therefore, be exchanged.
::It’s pretty difficult for me to discuss your ideas. I need more information. Here are a few questions:
- Does the worker perform one step or more steps?
- Is your workflow fixed, or may it vary or change in the future?
- Who triggers the processing of data? The data source (InputSource) or the data sink (Worker). This is essentially the question if your data processing is based on push (InputSource) versus pull (Worker). In the second case, it could be lazy.
- Is this data processing one thing or happens it permanently? I assume that because you wrote about an observer.
- Should the data processing be done single threaded or multithreaded?
My first assumption that this looks like a Model View Controller architecture. My second observation is different. Now, I’m thinking more about a Pipes-and-Filters architecture, but I need more information.
-
AuthorPosts
